
Privacy-preserving federated learning for healthcare diagnostics
Let’s be honest for a second. Healthcare diagnostics are, well, a bit of a paradox. On one hand, we’ve got AI models that can spot tumors in CT scans faster than a radiologist can blink. On the other hand, those same models need tons of patient data to learn — data that’s locked away in hospitals, clinics, and research centers. It’s like having a library full of books but being told you can’t open any of them. Frustrating, right?
Enter privacy-preserving federated learning. It sounds like a mouthful, but honestly, it’s one of the most elegant solutions to a problem that’s been haunting healthcare for years. Think of it as a study group where no one shares their actual notes — just the insights they gained from studying. No photocopies, no leaks, just smarter everyone.
What exactly is federated learning?
Well, traditionally, machine learning works like this: you gather all your data into one central server — a giant digital bucket — and train your model there. But in healthcare, that bucket is a legal minefield. Patient privacy laws like HIPAA in the US or GDPR in Europe make it nearly impossible to move sensitive data around.
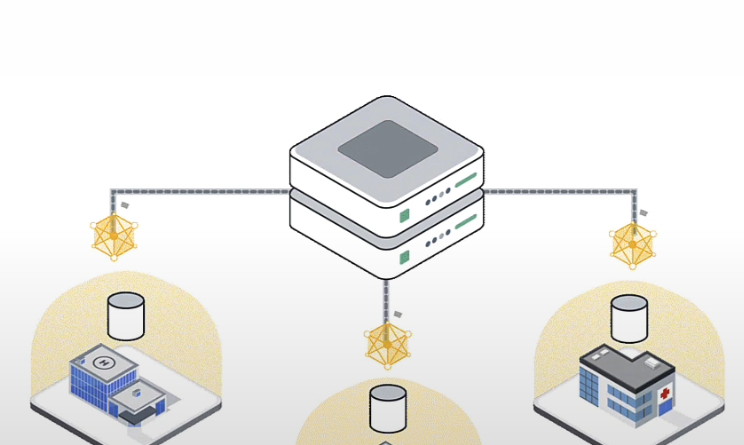
Federated learning flips the script. Instead of bringing data to the model, you bring the model to the data. Each hospital trains a local copy of the model on its own patient records. Then, only the model updates — the “learning” — get sent back to a central server. The raw data never leaves the building. It’s a bit like sending your diary to a friend but only letting them read the summary on the cover.
But here’s the kicker: privacy-preserving federated learning adds an extra layer. It uses techniques like differential privacy and secure multi-party computation to make sure even those model updates don’t reveal anything about individual patients. Noise is injected, data is shuffled, and the whole thing becomes a black box that still manages to learn.
Why healthcare diagnostics need this — yesterday
Look, diagnostics are getting scarily good. AI can now detect diabetic retinopathy from retinal scans, predict heart failure from ECG data, and even flag early signs of Alzheimer’s from speech patterns. But these models are only as good as the data they’re trained on. And right now, most of that data comes from a handful of well-funded hospitals in wealthy countries.
That creates a bias problem. A model trained mostly on data from, say, urban hospitals in the US might fail miserably when applied to a rural clinic in Southeast Asia. Federated learning can fix that — by pulling insights from diverse populations without ever moving their data. It’s like having a global brain that respects local borders.
The real-world pain points
Here’s where it gets messy. Hospitals are terrified of data breaches — and for good reason. A single leak can cost millions and destroy patient trust. Plus, different institutions use different electronic health record systems. Getting them to talk to each other is like herding cats. Privacy-preserving federated learning doesn’t just solve the privacy issue; it also sidesteps the interoperability nightmare. You don’t need a unified data format — just a unified model.
And then there’s the regulatory side. Sure, federated learning isn’t a magic bullet. Regulators are still figuring out how to audit these systems. But it’s a heck of a lot easier to get ethical approval for a project that never stores patient data off-site.
How it actually works — a quick breakdown
Okay, let’s get a little technical — but not too much. Imagine you’re training a model to spot pneumonia in chest X-rays. Here’s the step-by-step:
- A central server sends out a base model — like a blank template — to participating hospitals.
- Each hospital trains the model on its own X-ray data for a few rounds. The data never leaves the hospital’s server.
- Instead of sending back the data, each hospital sends back the updated model weights — basically, what the model learned.
- The central server averages these updates together, creating a new, improved global model.
- Rinse and repeat. Over time, the model gets smarter without ever seeing a single patient file.
But here’s the twist: with privacy-preserving techniques, those model weights are also scrambled. Differential privacy adds statistical noise so that even if someone intercepts the update, they can’t reverse-engineer individual patient data. It’s like telling someone the average height of a crowd without revealing who’s tall and who’s short.
Real examples you might have heard of
This isn’t just theory. Google Health used federated learning to train a model for detecting diabetic retinopathy across multiple hospitals in India and the US. The model performed almost as well as a centralized one — and without any data leaving the hospitals.
Another cool example: the MELLODDY project in Europe. That’s a consortium of pharmaceutical companies using federated learning to predict drug toxicity. Normally, these companies would never share their proprietary data. But with privacy-preserving federated learning, they can collaborate on models without giving away trade secrets. It’s like competing chefs sharing cooking tips without revealing their secret ingredients.
But is it perfect? Not even close
Let’s not sugarcoat it. Privacy-preserving federated learning has some serious challenges. For one, it’s computationally expensive. Training a model locally at 50 different hospitals requires serious hardware. Not every clinic has a GPU cluster lying around.
Then there’s the communication bottleneck. Sending model updates back and forth over the internet — especially with differential privacy noise added — can slow things down. It’s like trying to have a conversation through a thick wall. You hear the gist, but you miss some nuance.
And here’s a weird one: model poisoning. What if a malicious hospital sends corrupted updates on purpose? The central server has to be smart enough to detect and filter those out. It’s a cat-and-mouse game that’s still evolving.
Where it shines brightest
That said, for certain diagnostics, the trade-offs are totally worth it. Think about rare diseases. A single hospital might only see five cases a year. But across 100 hospitals, you’ve got 500 cases. Federated learning lets you train a robust model on that rare condition without anyone having to share patient identities. It’s a game-changer for orphan diseases.
Or consider cancer pathology. Different labs stain slides differently. A model trained on one lab’s slides might not generalize. Federated learning lets models learn from multiple staining styles — again, without moving the slides.
A quick comparison: centralized vs. federated
| Aspect | Centralized Learning | Privacy-preserving Federated Learning |
|---|---|---|
| Data location | Moved to central server | Stays at local institutions |
| Privacy risk | High — single point of breach | Low — data never leaves |
| Regulatory ease | Difficult (HIPAA, GDPR) | Easier to approve |
| Model performance | Usually best | Close, but slightly lower due to noise |
| Infrastructure cost | High for central server | Distributed — each site needs compute |
| Data diversity | Limited to what’s collected | Can tap into global datasets |
See the trade-off? You lose a tiny bit of model accuracy, but you gain massive privacy and scalability. For most diagnostic use cases, that’s a deal worth taking.
What’s next on the horizon
Honestly, we’re still in the early days. Researchers are working on vertical federated learning — where different hospitals hold different features for the same patients. Imagine one hospital has lab results, another has imaging, and a third has genetic data. Federated learning could combine those insights without merging the databases. It’s like assembling a puzzle where each person holds a few pieces but never sees the full picture.
There’s also federated transfer learning, where a model pre-trained on a large public dataset gets fine-tuned on private hospital data. That speeds up training and reduces the amount of local data needed. For smaller clinics, that’s huge.
And let’s not forget the rise of edge devices. Wearables like smartwatches already collect heart rate and ECG data. Privacy-preserving federated learning could let those devices train diagnostic models right on the wrist — no cloud upload needed. Your watch could learn to detect arrhythmias without ever sending your heartbeat to a server. That’s the future we’re heading toward.
The bottom line — no, really
Privacy-preserving federated learning isn’t a silver bullet. It’s messy, it’s imperfect, and it requires a lot of coordination. But in a world where patient data is both incredibly valuable and incredibly vulnerable, it might be the only realistic path forward for global healthcare diagnostics.
Think about it this way: we’re not asking hospitals to trust each other. We’re asking them to trust the math. And math, unlike people, doesn’t leak secrets. It doesn’t get hacked. It just… learns. Quietly. Safely.
So next time you hear about AI diagnosing a disease faster than a human, remember — the real magic isn’t in the algorithm. It’s in how we let it learn without prying. That’s the kind of progress worth protecting.